Zuerst ein Beispiel:
Vor der Entwicklung von relationalen Datenbank-Managementsystemen (DBMS) wurden zunächst hierarchische DBMS (Ein-Vater-viele-Kinder) und dann Netzwerk-DBMS (Ein-Vater-viele-Kinder plus ein-Kind-viele-Eltern) eingesetzt. Beide hatten den Nachteil, daß man s ich sowohl bei der Datenspeicherung, als auch bei Datenabfragen mit der inneren Struktur der Datenhaltung auskennen und beschäftigen mußte. Speziell bei den Abfragen ging es häufig darum, irgendwelchen Zeigern von einem gefundenen Datensatz zu seinem Vater oder den Kindern zu folgen. Dies war sehr kompliziert, konnte nur von DB-Experten durchgeführt werden und deckte trotzdem nicht alle Anforderungen ab.
Dann wurde 1970 von Ted Codd (IBM, San Jose Research Lab) das zunächst theoretische Modell der relationalen Datenbankmanagementsysteme (RDBMS) entwickelt. Erste kommerzielle relationale Datenbanksysteme wurden dann zwischen 1975-1980 entwickelt (DB2 von IBM, ORACLE von Oracle Corporation u.a.).
Folgende 6 Punkte sollte ein relationales DBMS erfüllen [SQL01, S.21]:
Auf den tabellarisch gespeicherten Daten müssen mit der Hochsprache fünf elementare relationale Operationen durchgeführt werden können, damit diese Sprache als »relational vollständig« gilt:
Weiter sollten noch folgende zusammengesetzte Operatoren vorhanden sein:
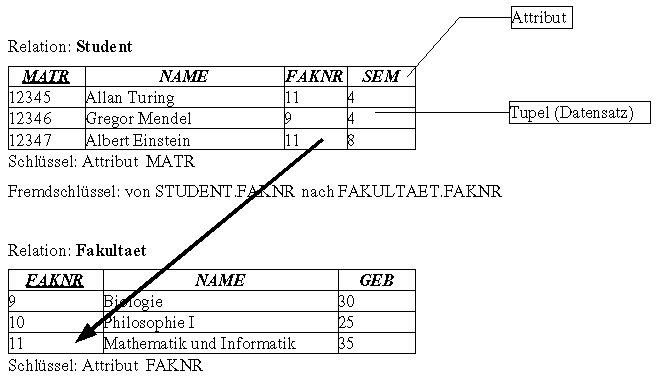
Von den zusammengesetzten Operationen ist speziell die Operation »Join« in relationalen Datenbanken eine der am häufig benötigtsten Operationen. Sie ermöglicht es, die Daten in den Tabellen möglichst redundanzfrei zu halten. Das Beispiel am Anfang dieses Kapitels zeigt bereits, daß hier für zwei verschiedene Objektarten aus der realen Welt (Student, Fakultät) zwei verschiedene Tabellen angelegt wurden. Es wird nicht bei jedem Studenten der Name seiner Fakultät abgelegt (spart Speicherplatz!). Und es wird auch nicht das Gebäude in der Studentenrelation abgelegt (einfachere Wartung, wenn die Fakultät das Gebäude einmal wechseln sollte).
In dem Fall der Fragestellung bei »8.Join«(siehe oben) muß ein JOIN über das Attribut »FAKNR« gemacht werden. Es kann also zuerst in der Studentenrelation der Student anhand seiner Matrikelnummer gesucht werden und dann anhand der Fakultätsnummer des Stud enten in der Fakultätenrelation die passende Gebäudenummer.
[Structured Query Language = SQL sprich: »sequel« (engl. Folge, Nachspiel)]
Eng verknüpft mit der Entwicklung von RDBMS war die Entwicklung einer einheitlichen Hochsprache für Datenbankabfragen. Der Vorgänger von SQL hieß SEQUEL und wurde Mitte der 70'er Jahre von IBM vorgestellt und zusammen mit dem Prototypen der relationalen Da tenbank »System R« (1975-1979) verwendet. 1977 fing die spätere Oracle Corporation ebenfalls mit der Entwicklung eines RDBMS an, das auf SQL basierte. 1979 wurde »Oracle Vers.1« fertiggestellt.
Durch zwei große Produkte von IBM (DB2 und SQL/DS) und die Datenbank Oracle wurde SQL zum defacto Industriestandard für relationale Datenbanksysteme. ANSI und ISO-Normungen folgten.
Die Syntax der drei wichtigsten Datenbankaktionen in SQL soll hier nun kurz besprochen werden: Tabellen anlegen, Daten in Tabellen füllen und Daten abfragen. Dabei sind die Syntaxdiagramme nicht vollständig, sondern ermöglichen wiederum nur die Basisfunkti onalität der Befehle.
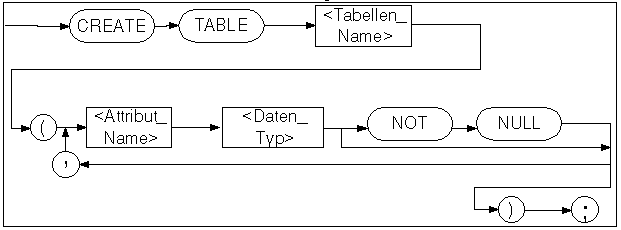
Die Studententabelle auf der ersten Grafik dieses Kapitels wird zum Beispiel so angelegt:
CREATE TABLE Student ( MATR INTEGER NOT NULL, NAME VARCHAR (30), FAKNR INTEGER, SEM INTEGER);
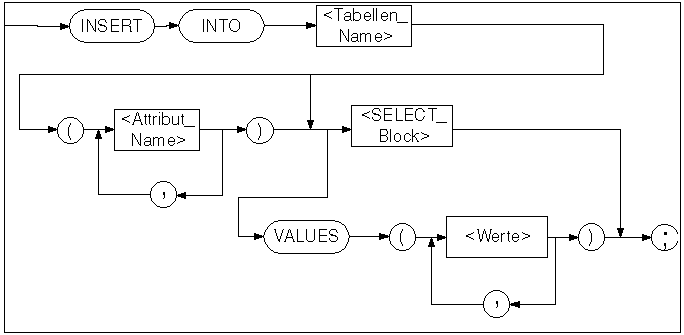
Um nun den Datensatz von 'Allan Turing' einzufügen:
INSERT INTO Student VALUES (12345, 'Allan Turing', 11, 4);
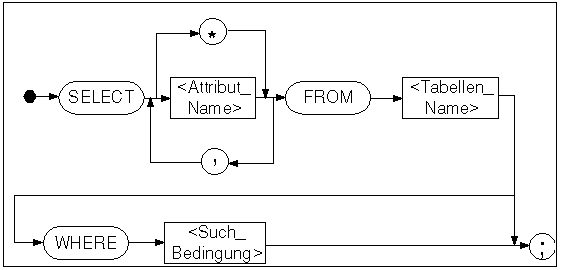
Wenn man nun alle Studenten, die im vierten Semester sind, ermitteln möchte:
SELECT * FROM Student WHERE SEM=4;
liefert diese Ergebnismenge:
MATR NAME FAKNR SEM ---- --------------- ---- ---- 12345 Allan Turing 11 4 12346 Gregor Mendel 9 4
Um nun den oben bereits erwähnten JOIN durchzuführen, der das Gebäude der Fakultät des Studenten mit der Matrikelnummer 12347 ermittelt, muß folgende Abfrage durchgeführt werden.
SELECT Fakultaet.GEB
FROM Student, Fakultaet
WHERE Student.MATR = 12347
AND Fakultaet.FAKNR = Student.FAKNR;